 VeryPDF Screen OCR官方版 v2.2VeryPDF Screen OCR官方版 v2.2官方下载
VeryPDF Screen OCR官方版 v2.2VeryPDF Screen OCR官方版 v2.2官方下载
 日杂相机
日杂相机 嗨格式录屏大师Mac版官方版 v1.1
嗨格式录屏大师Mac版官方版 v1.1 Web Snapper Mac版V3.3.8
Web Snapper Mac版V3.3.8 截图Mac版V2.0.0
截图Mac版V2.0.0 Snagit for macV3.3.3
Snagit for macV3.3.3 Screenshot Path for macV1.2.2
Screenshot Path for macV1.2.2 preCut Pro V3.05
preCut Pro V3.05VeryPDF Screen OCR官方版是一款十分出色的屏幕ocr截图识别软件,VeryPDF Screen OCR官方版界面美观大方,功能强劲实用,支持截图功能,能够从扫描的PDF页面、图像、受保护的网页。
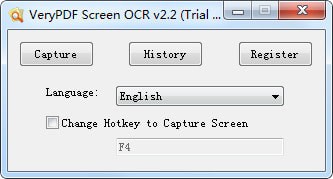
能够识别计算机屏幕上任何区域显示的字符。
识别任何扫描文件中的字符,并将其转换为可编辑文本。
捕获阻止复制的网页上的文本。
能够识别英语、法语、丹麦语、德语、意大利语、荷兰语、西班牙语、葡萄牙语、希腊语、越南语、汉语、保加利亚语、加泰罗尼亚语、匈牙利语等文本。
自动将屏幕快照和识别的文本保存在计算机上。
能够将捕获的截图复制到剪贴板。
能够与其他人在线共享捕获的屏幕快照。
提供菜单项以查看已保存图像的目录。
允许您查看屏幕截图和文本内容的历史记录。
选项将屏幕截图保存在磁盘上并将路径复制到剪贴板。
VeryPDF Screen OCR官方版能够自定义要捕获的热键。
系统启动后自动运行的选项。
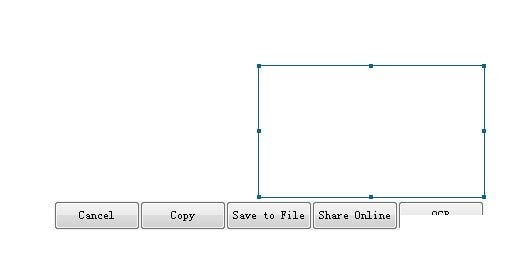
识别所选区域中的文本
Verypdf屏幕OCR能够识别计算机屏幕上任何选定区域中的文本,包括不能用鼠标突出显示的区域。Verypdf屏幕OCR使您能够将屏幕上任意位置的任何字符转换为可编辑和可研究的文本。
识别屏幕上的多语言文本
Verypdf屏幕OCR支持多种语言,包括英语、法语、丹麦语、德语、意大利语、荷兰语、西班牙语、葡萄牙语、希腊语、越南语、汉语、保加利亚语、加泰罗尼亚语、匈牙利语、印度尼西亚语等。Verypdf屏幕OCR能够识别多种语言的文本。
识别现有图像中的文本
除了识别屏幕快照中的文本外,Verypdf屏幕OCR还能够识别计算机上现有图像中的文本。用户可以将这些图像导入到进程队列,并使用应用程序识别图像中的文本,就像识别屏幕快照一样。

识别屏幕上的文本
当您看到如上所示的对话框时,请按如下操作使用verypdf screen ocr来识别屏幕上的文本。
单击“语言”组合框左侧的小箭头,从下拉列表中选择正确的语言。
如果文本是英文的,可以跳到下一个小步骤。
在“Verypdf屏幕OCR”对话框中单击“捕获”。然后,屏幕将被冻结。
按住鼠标左键并在计算机屏幕上选择一个区域。
点击“OCR”按钮。
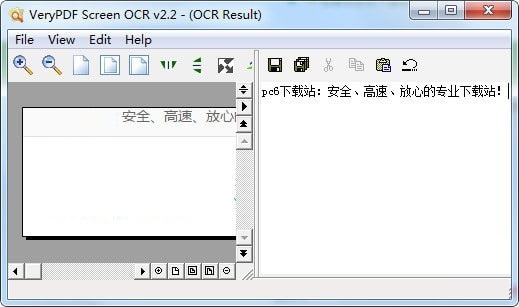
一分钟后,您将看到屏幕上出现“OCR结果”窗口。这个接口可以分为两部分。在左侧显示屏幕截图;在右侧显示OCR结果。